Chapter 2: Object Publishing
Introduction
Zope puts your objects on the web. This is called object publishing. One of Zope's unique characteristics is the way it allows you to walk up to your objects and call methods on them with simple URLs. In addition to HTTP, Zope makes your objects available to other network protocols including FTP, WebDAV and XML-RPC.
Anonymous User - Feb. 1, 2005 9:05 am: This article should be very informative. But it is really confusing with a lot of useful, useless, contradicting comments. Please some one, who is capable enough or the author should make an effort of rewriting this.
Anonymous User - Mar. 3, 2005 7:40 am: has anyone else noticed how many useless comments get saved here for ever and ever?
Anonymous User - Mar. 4, 2005 11:49 pm: I want to use Zope as a XML-RPC server on Windows 2003 with minimal configuration. Thogh installation is easy, I am totally lost and do not know how to put my Python class/method exposed to client via Zope (External methods?). Google keywords "Zope XML RPC" does not get enough clues. Many articles just tell you Zope supports it and then continue the coding stuff. I think it's better create a Quick Start region for Zope document.
Anonymous User - Mar. 4, 2005 11:57 pm: More on the organization of the document and comments. Though comments are useful addition information if someone is dedicate to curate them (like I have seen in MySQL document), in most case, they just interrupt the understanding of the documents. I suggest create a single forum like many J2EE open source project (JBoss, Spring, Hibernate). I am a novice in Zope and really need some useful help online.
In this chapter you'll find out exactly how Zope publishes objects. You'll learn all you need to know in order to design your objects for web publishing.
HTTP Publishing
When you contact Zope with a web browser, your browser sends an
HTTP request to Zope's web server. After the request is completely
received, it is processed by ZPublisher, which is Zope's object
publisher. ZPublisher is a kind of light-weight ORB (Object
Request Broker). It takes the request and locates an object to
handle the request. The publisher uses the request URL as a map to
locate the published object. Finding an object to handle the
request is called traversal, since the publisher moves from
object to object as it looks for the right one. Once the published
object is found, the publisher calls a method on the published
object, passing it parameters as necessary. The publisher uses
information in the request to determine which method to call, and
what parameters to pass. The process of extracting parameters from
the request is called argument marshalling. The published object
then returns a response, which is passed back to Zope's web
server. The web server, then passes the response back to your web
browser.
Anonymous User - Dec. 21, 2001 8:39 am - I don't understand.Sorry.
Anonymous User - Jan. 11, 2002 9:53 am - Maybe clarify, that "Web Server" is just the front end, passing requests to and receiving responses from ZPublisher, ZPublisher mapping requests to responses?
tibi - Feb. 22, 2002 6:00 am - Prehaps give an example at this point: say the URL http://zope/animals/monkey/feed?fruit=banana&num=17 is translated in Python to the call animals.monkey.feed(fruit = banana, num = 17)
Jace - July 8, 2002 5:41 am: In the above example, the actual call will be animals.monkey.feed(fruit = "banana", num = "17"). Note that they are passed as strings. If the second parameter was meant to be passed as an integer, the URL should have been "http://zope/animals/monkey/feed?fruit=banana&num:int=17.
Anonymous User - Aug. 9, 2002 12:29 am: Last 2 comments are illustrative and helpful and might be expanded upon.
Anonymous User - Sep. 4, 2002 11:24 pm: num:int is not a standard convention
Anonymous User - Oct. 4, 2002 10:55 pm: num:int nevertheless is part of Zope and above examples are on the right track: exemplify URL traversal as July 8 above; point out "feed" need not be contained in ~/monkey (acquisition) and pattern Form/Action/Response is eased by num:int (conversion) (with [apologies for lack of]![refs to] detail) then reader may see the promised land. How ease it is to publish objects...:)blf
Anonymous User - Dec. 31, 2002 2:54 pm: What is the significance of the phrase "After the request is completely received". What is the difference between receiving the request and "completely" receiving the the request?
Anonymous User - Dec. 2, 2003 5:44 am: Some web servers start to process the HTTP request when it partially arrives at the server. Imagine for example a huge file upload. When the header is already at the server some action may be taken to check if the client is allowed to upload any file at all. This may help to prevent DOS attacks that upload huge files which are discarded but only after they were processed and put a huge load on the server.
Anonymous User - Jan. 14, 2005 7:56 am: It's not a *published object*, rather it's an Zope object *to be published*. The incorrect use of *published* is a huge source of confusion. The publisher *publishes* the attributes of Zope object, an object yet to be published.
The publishing process is summarized in [2-1]

Figure 2-1 Object publishing
limaye - Sep. 25, 2002 5:21 pm: The Zope side [the server side of the above figure] can be thought of as a collection of containers [zope server container, zope publisher container, etc.] - each responsible for managing a set of issues [e.g., the zope server container manages "sessions" with its clients (http, ftp, webdav, xml-rpc) and could also decide on the issues like load balancing, security etc.] The zope publisher container can provide services of mapping the URL path to the zope object and of dispatching the request; prior to dispatching the request the publisher would also validate the access control constraints; help provide transaction control; load the object in memory; provide life cycle support to these zope objects; provide the object[method invocation] with a "context" so on and so forth. As it may be obvious there is an entity relationship between each of these containers and their childern - whose focus is on managing the call control issues - this hierarchy of containers is used to provide a framework in which the zope objects can do the job on hand without worrying too much about the middleware issues. With the above paragraph setting the technical framework now [hopefully] you can see the value of interfaces. They help publish a contract [e.g. a "set" of interfaces need to be implemented by any zope object (or by the zope framework components themselves) so as to be integrated within the zope framework] which is implemented by the "publishers" (don't confuse this with Zope Publisher) and consumed by the consumers. The other good feature about the interfaces is that the consumer (which can be more than 1) need not worry about who implements the interface and can safely assume that the invocations will be properly processed - in case of an error the publisher of the interface will throw the appropriate exception to report it. MSL
Typically the published object is a persistent object that the published module loads from the ZODB. See Chapter 4 for more information on the ZODB.
Anonymous User - Jan. 11, 2002 10:09 am - What is the difference between "published module" and "published object"? how can a module get "published"?
pratyush - May 28, 2004 3:25 am: what is exactly a published module u didnt not mention it any where it would be better to give a n example for that one
sriram - May 28, 2004 3:30 am: i m not getting exactly the thing please say it clearly
This chapter will cover all the steps of object publishing in detail. To summarize, object publishing consists of the main steps:
- The client sends a request to the publisher
- The publisher locates the published object using the request URL as a map.
- The publisher calls the published object with arguments from the request.
- The publisher interprets and returns the results to the client.
The chapter will also cover all the technical details, special cases and extra-steps that this list glosses over.
Anonymous User - Dec. 31, 2002 2:56 pm: Previously, it was written that the objects response was passed back to the web browser by the Zope web server. Then it was written that the object's respoce was "interpreted" by ZPublisher. Which is true? What does "interepreted" mean?
terry - Apr. 29, 2003 10:27 pm: This section omits a useful piece of information -- where does Zope get the first object? This information is in Ch 7, but deeply buried, so I actually got the answer from the mailing list. I think you need a reference here too: import Zope root_object = Zope.app() Doing a dir(root_object) will show you your root folder in your Zope instance! Which is really cool for development testing and introspecting your existing objects.
URL Traversal
Traversal is the process the publisher uses to locate the published object. Typically the publisher locates the published object by walking along the URL. Take for example a collection of objects:
class Classification:
...
class Animal:
...
def screech(self, ...):
...
vertebrates=Classification(...)
vertebrates.mammals=Classification(...)
vertebrates.reptiles=Classification(...)
vertebrates.mammals.monkey=Animal(...)
vertebrates.mammals.dog=Animal(...)
vertebrates.reptiles.lizard=Animal(...)
Anonymous User - June 1, 2003 2:13 am:
class Classification:
...
class Animal:
...
def screech(self, ...):
...
vertebrates=Classification(...)
vertebrates.mammals=Classification(...)
vertebrates.reptiles=Classification(...)
vertebrates.mammals.monkey=Animal(...)
vertebrates.mammals.dog=Animal(...)
vertebrates.reptiles.lizard=Animal(...)
This collection of objects forms an object hierarchy. Using Zope
you can publish objects with URLs. For example, the URL
http://zope/vertebrates/mammals/monkey/screech, will traverse
the object hierarchy, find the monkey object and call its
screech method.
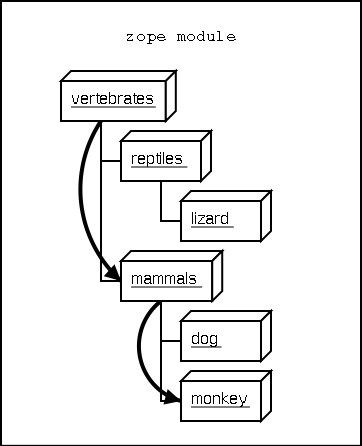
Figure 2-2 Traversal path through an object hierarchy
The publisher starts from the root object and takes each step in the URL as a key to locate the next object. It moves to the next object and continues to move from object to object using the URL as a guide.
Typically the next object is a sub-object of the current object
that is named by the path segment. So in the example above, when
the publisher gets to the vertebrates object, the next path
segment is "mammals", and this tells the publisher to look for a
sub-object of the current object with that name. Traversal stops
when Zope comes to the end of the URL. If the final object is
found, then it is published, otherwise an error is returned.
Anonymous User - Jan. 11, 2002 10:15 am - url not found: mammals
Anonymous User - Nov. 19, 2002 1:40 am: Sometimes the object published is not the one at the end of the URL. Sometimes an object before the end is published and extra segments on the URL are fed to it as parameters.
Jace - Feb. 28, 2005 6:38 am: Not necessarily. The rest of the path will be fed as parameters only if you have a traversal hook (see below). Else the publisher will attempt to load those objects via acquisition, and cry 404 if NotFound.
Now let's take a more rigorous look at traversal.
Traversal Interfaces
Zope defines interfaces for publishable objects, and publishable modules.
Anonymous User - Jan. 11, 2002 10:20 am - typo? no "," before "and"
Anonymous User - Aug. 26, 2002 3:43 am: There is no typo at all, no comma is needed here.
Anonymous User - Oct. 18, 2005 6:42 pm: There is a typo now. Please remove the comma before "and". It might be equally clear to say "Zope defines interfaces for publishable objects and modules."
When you are developing for Zope you almost always use the
Zope package as your published module. However, if you are
using ZPublisher outside of Zope you'll be interested in the
published module interface.
Anonymous User - Dec. 5, 2001 8:32 am - please clarify 'your published module'
Anonymous User - Jan. 8, 2002 3:53 pm - I think a "published module" is the code that is running and listening on a certain port number to handle requests (over http, ftp, etc.). So my interpretation is that the statement "use the Zope package as your published module" means "install your component into Zope let Zope publish it".
Anonymous User - Jan. 11, 2002 10:24 am - new term "Zope package". never had that one
Anonymous User - Sep. 30, 2002 7:10 am: Using the Zope package as your published module: Does this intend, that your objects are contained in the ZODB (eq ZOPE package)?
Publishable Object Requirements
Zope has few restrictions on publishable objects. The basic rule is that the object must have a doc string. This requirement goes for method objects too.
Another requirement is that a publishable object must not have a name that begin with an underscore. These two restrictions are designed to keep private objects from being published.
Anonymous User - Jan. 11, 2002 10:25 am - typo? begin --> begins
Anonymous User - Jan. 11, 2002 10:39 am - following paragraph: why can't python modules not be published? Why the is a "Published Module" in picture 2-1? And what is the diff. between a module and a module object? fuzzy terms blur semantic categories.
Anonymous User - Aug. 16, 2003 12:27 pm: What does 'fuzzy terms blur semantic categories' mean? Please explain or delete.
Anonymous User - May 28, 2004 3:57 am: this content is nice but u didn't mention about the "doc string"(it is the restriction )u mean .doc oor DTKL method of thing. It would be better to give an example to the restriction so that the devoloper can practice. thank you
Finally, published objects cannot be Python module objects.
Traversal Methods
ZPublisher
cuts the URL into path elements
delimited by slashes, and uses each path element to traverse
from the current object to the next object.
ZPublisher
locates the next object in one of three ways:
- Using
__bobo_traverse__ - Using
getattr - Using dictionary access.
First the publisher attempts to call the traversal hook
method, __bobo_traverse__. If the current object has this
method it is called with the request and the current path
element. The method should return the next object or None to
indicate that a next object can't be found. You can also
return a tuple of objects from __bobo_traverse__ indicating
a sequence of sub-objects. This allows you to add additional
parent objects into the request. This is almost never
necessary.
Anonymous User - Jan. 11, 2002 10:43 am - typo? method, --> method maurer mentions also "__before_publishing_traverse__".
Anonymous User - June 4, 2002 11:10 am: It might be nice to have a footnote briefly describing where "bobo" came from. Storks don't count.
Anonymous User - July 12, 2002 2:50 pm: It might be nicer to get rid of the "bobo" name altogether, why can't this be called __traverse__ ? Probably too much legacy code out there.
Anonymous User - Aug. 16, 2003 12:29 pm: Storks do count. Or at least research indicates that they possess the ability - although only up to '2'.
Here's an example of how to use '__bobo_traverse__':
def __bobo_traverse__(self, request, key):
# if there is a special cookie set, return special
# subobjects, otherwise return normal subobjects
if request.cookies.has_key('special'):
# return a subobject from the special dict
return self.special_subobjects.get(key, None)
# otherwise return a subobject from the normal dict
return self.normal_subobjects.get(key, None)
warpeace - Feb. 17, 2004 11:14 am: The above example is incomplete. This would work fine when called from a normal web request i.e. from BaseRequest.Traverse. However, when an object containing this __bobo_traverse__ is traversed through ObjectItem.unrestrictedTraverse or ObjectItem.restrictedTraverse, then the request object passed to __bobo_traverse__ contains a single key i.e 'TraversalRequestNameStack'. In this case the attibute access 'request.cookies' would raise an AttributeError. As an example of this consider that you call your object from the ZMI i.e. say http://localhost:8080/my_bobo_object/manage_workspace. Now, in manage_workspace, my_bobo_object is again traversed using 'unrestrictedTraverse' which would cause a very unwieldy 'TypeError'of 'You are not authorized to view this object' and this can be very difficult to track down. One very rudimentary solution to above __bobo_traverse__ would be: def __bobo_traverse__(self, request, key): if hasattr(request, cookies): blah... else: # probably from unrestrictedTraverse return getattr(self, key) Of course, it would be helpful if some one could point out a more generic and an elegant solution.
warpeace - Feb. 17, 2004 11:14 am: The above example is incomplete. This would work fine when called from a normal web request i.e. from BaseRequest.Traverse. However, when an object containing this __bobo_traverse__ is traversed through ObjectItem.unrestrictedTraverse or ObjectItem.restrictedTraverse, then the request object passed to __bobo_traverse__ contains a single key i.e 'TraversalRequestNameStack'. In this case the attibute access 'request.cookies' would raise an AttributeError. As an example of this consider that you call your object from the ZMI i.e. say http://localhost:8080/my_bobo_object/manage_workspace. Now, in manage_workspace, my_bobo_object is again traversed using 'unrestrictedTraverse' which would cause a very unwieldy 'TypeError'of 'You are not authorized to view this object' and this can be very difficult to track down. One very rudimentary solution to above __bobo_traverse__ would be: def __bobo_traverse__(self, request, key): if hasattr(request, cookies): blah... else: # probably from unrestrictedTraverse return getattr(self, key) Of course, it would be helpful if some one could point out a more generic and an elegant solution.
This example shows how you can examine the request during the traversal process.
If the current object does not define a __bobo_traverse__
method, then the next object is searched for using getattr.
This locates sub-objects in the normal Python sense.
If the next object can't be found with getattr, ZPublisher
calls on the current object as though it were a
dictionary. Note: the path element will be a string, not an
integer, so you cannot traverse sequences using index numbers
in the URL.
a
is the current object, and
next
is
the name of the path element. Here are the three things that
ZPublisher
will try in order to find the next object:
-
a.__bobo_traverse__("next") -
a.next -
a["next"]
Anonymous User - Jan. 18, 2002 6:13 pm - In the definition above there are three arguments. Where is the "request" argument here?
If the next object isn't found by any of these means
ZPublisher returns a HTTP 404 (Not Found) exception.
Publishing Methods
Once the published object is located with traversal, Zope
publishes it in one of three possible ways.- Calling the published object
- If the published object is a function or method or other callable object, the publisher calls it. Later in the chapter you'll find out how the publisher figures out what arguments to pass when calling.
- Calling the default method
- If the published object is not
callable, the publisher uses the default method. For HTTP
GETandPOSTrequests the default method isindex_html. For other HTTP requests such asPUTthe publisher looks for a method named by the HTTP method. So for an HTTPHEADrequest, the publisher would call theHEADmethod on the published object. - Stringifying the published object
- If the published object
isn't callable, and doesn't have a default method, the
publisher publishes it using the Python
strfunction to turn it into a string.
shh - Jan. 13, 2003 10:24 am: The order given in this paragraph is INCORRECT. If you look at the traverse() method you will find that ZPublisher tries the default method *first*, and only if this fails goes on with __call__() and __str__().
Anonymous User - Jan. 14, 2005 7:59 am: In the text: "Once the published object is ... " should read: "Once the publishable object is ..."
After the response method has been determined and called, the publisher must interpret the results.
Anonymous User - Jan. 11, 2002 10:52 am - What if the called method returns another callable object? is it like as long as callable objects are there, they are called, the resulting object (eg image) rendered [term used by maurer] or is Image a class w a method __call__.
HTTP Responses
Normally the published method returns a string which is
considered the body of the HTTP response. The response
headers can be controlled by calling methods on the response
object, which is described later in the chapter. Optionally,
the published method can return a tuple with the title, and
body of the response. In this case, the publisher returns an
generated HTML page, with the first item of the tuple used
for the HTML title of the page, and the second item as the
contents of the HTML body tag. For example a response of:
('response', 'the response')
Anonymous User - May 18, 2002 8:10 pm: Typo - "returns an generated" should be "a generated."
is turned into this HTML page:
<html> <head><title>response</title></head> <body>the response</body> </html>
Controlling Base HREF
When you publish an object that returns HTML relative links should allow you to navigate between methods. Consider this example:
class Example:
"example"
def one(self):
"method one"
return """<html>
<head>
<title>one</title>
</head>
<body>
<a href="two">two</a>
</body>
</html>"""
def two(self):
"method two"
return """<html>
<head>
<title>two</title>
</head>
<body>
<a href="one">one</a>
</body>
</html>"""
Anonymous User - Jan. 21, 2002 12:34 pm - need a comma there: "...an object that returns HTML, relative links..."
The relative links in methods one and two allow you to
navigate between the methods.
Anonymous User - Jan. 11, 2002 10:56 am - typo (syntax) "When you... ." stumbled over this sentence.
However, the default method, index_html presents a
problem. Since you can access the index_html method
without specifying the method name in the URL, relative
links returned by the index_html method won't work
right. For example:
class Example:
"example"
def index_html(self):
return """<html>
<head>
<title>one</title>
</head>
<body>
<a href="one">one</a><br>
<a href="two">two</a>
</body>
</html>"""
...
If you publish an instance of the Example class with the
URL http://zope/example, then the relative link to method
one will be http://zope/one, instead of the correct
link, http://zope/example/one.
Anonymous User - Feb. 28, 2002 2:30 pm - I believe it is still unclear just why the address of the the method "one" is not http://zope/example/one.
Anonymous User - July 17, 2002 5:47 pm: Relative links replace the last component of the URL. From http://zope/example, a relative link to href="one" takes you to http://zope/one. From http://zope/example/, a relative link to href="one" would take you to http://zope/example/one. Seemed clear enough to me.
limaye - Sep. 25, 2002 7:35 pm: For the link http://zope/example/introduction - where introduction is a zope object [contained in folder example] could have reference to relative links "one", "two" so on. Now the relative link at the level of introduction [i.e. in folder example - read on] would be interpreted by zope as http://zope/example/one, http://zope/example/two etc. But now consider the case that you give http://zope/example [in this case assume that there is no node following it and assume that there is a default method called index_html]; Further assume that index_html duplicates the content of introduction above - then in this scenario "one", "two" would be interpreted relative node "example" and subsequently it would be replaced by zope as http://zope/one and http://zope/two - which is not what you wanted. If you consider the / as signifying the folder object then http://zope/example can be interpreted as example contained in folder zope. While http://zope/example/ would be interpreted as objects contained in folder example and hence the relative link "one" would be interpreted correctly relative to http://zope/example/ to mean relative to folder example; while in the case of http://zope/example a relative link "one" would be interpreted relative to folder zope. I hope this explanation helps. MSL
consultit - Mar. 3, 2005 5:18 am: The correct sentence should be something similar to: "If you publish an instance of the Example class, using one of the following URLs http://zope/example and http://zope/example/index_html, then, in the second case, the relative link to method one will be http://zope/example/index_html/one, instead of the correct link, http://zope/example/one." But this problem should arise only if the 'one' method cannot be aquired from the example 'object' (?)
Zope solves this problem for you by inserting a base tag
inside the head tag in the HTML output of index_html
method when it is accessed as the default method. You will
probably never notice this, but if you see a mysterious
base tag in your HTML output, know you know where it came
from. You can avoid this behavior by manually setting your
own base with a base tag in your index_html method
output.
berniey - Oct. 24, 2001 6:27 am - A little typo. "know you know where it came from" should be "now you know where it came from"
Anonymous User - Dec. 5, 2002 2:49 pm: Can we have an example or a link to the syntax to dynamically generate a corrected base for a virtual hosting context.
Response Headers
The publisher and the web server take care of setting response
headers such as Content-Length and Content-Type. Later in
the chapter you'll find out how to control these headers.
Later you'll also find out how exceptions are used to set the
HTTP response code.
Pre-Traversal Hook
The pre-traversal hook allows your objects to take special action before they are traversed. This is useful for doing things like changing the request. Applications of this include special authentication controls, and virtual hosting support.
If your object has a method named
__before_publishing_traverse__, the publisher will call it
with the current object and the request, before traversing
your object. Most often your method will change the
request. The publisher ignores anything you return from the
pre-traversal hook method.
The ZPublisher.BeforeTraverse module contains some functions
that help you register pre-traversal callbacks. This allows
you to perform fairly complex callbacks to multiple objects
when a given object is about to be traversed.
Anonymous User - Jan. 11, 2002 11:49 am - Why register needed. isn't it sufficient for the object to have a __*__-method?
Anonymous User - Jan. 17, 2002 8:20 am - chrism - BeforeTraverse sticks in a method "__before_publishing_traverse__", usually on "containerish" (folderish) objects. __before_publishing_traverse__ is a method that calls the callbacks that you register. For example, this is how "AccessRules" and "SiteRoots" work - they register arbitrary callbacks with __before_publishing_traverse__. __before_publishing_traverse__ is called before __bobo_traverse__ of the same object in order to give virtual hosting a chance to do its job. It calls all of the callbacks that are registered with it. Note that because of the time at which it's called in the traversal process, callbacks that get registered with it have no access to authentication info.
Anonymous User - Jan. 18, 2002 6:22 pm - Thanks for the explanation! More information and an example here is really needed.
Traversal and Acquisition
Acquisition affects traversal in several ways. See Chapter 5,
"Acquisition" for more information on acquisition. The most
obvious way in which acquisition affects traversal is in
locating the next object in a path. As we discussed earlier, the
next object during traversal is often found using
getattr. Since acquisition affects getattr, it will affect
traversal. The upshot is that when you are traversing objects
that support implicit acquisition, you can use traversal to walk
over acquired objects. Consider the object hierarchy rooted in
'fruit':
from Acquisition import Implicit
class Node(Implicit):
...
fruit=Node()
fruit.apple=Node()
fruit.orange=Node()
fruit.apple.strawberry=Node()
fruit.orange.banana=Node()
When publishing these objects, acquisition can come into
play. For example, consider the URL /fruit/apple/orange. The
publisher would traverse from fruit, to apple, and then
using acquisition, it would traverse to orange.
Mixing acquisition and traversal can get complex. Consider the URL /fruit/apple/orange/strawberry/banana. This URL is functional but confusing. Here's an even more perverse but legal URL /fruit/apple/orange/orange/apple/apple/banana.
Anonymous User - Sep. 30, 2002 8:05 am: Would be <b>/fruit/apple/banana/orange/strawberry illegal</b>?
Anonymous User - Oct. 8, 2002 9:35 pm: I think so. Someone more experienced, please confirm. (I have not yet read the chapter on acquisition).
Anonymous User - Nov. 17, 2003 5:05 am: yes it is illegal. You have to think of it in "context". An object has to be found in the context of the previous objects. banana is in the context of orange, but in the path orange is nowhere to be found BEFORE banana. So it won't be found. strawberry will be found because apple is in the path before strawberry. Should you express it as */fruit/apple/orange/banana/strawberry* it should work cause each object can be found in the context of some other object that is in the path BEFORE the object you want to find... You really should read the USER Manual (zope book), especially the chapter about acquisition. it really qlarifies the concept
In general you should limit yourself to constructing URLs which use acquisition to acquire along containment, rather than context lines. It's reasonable to publish an object or method that you acquire from your container, but it's probably a bad idea to publish an object or method that your acquire from outside your container. For example:
from Acquisition import Implicit
class Basket(Implicit):
...
def numberOfItems(self):
"Returns the number of contained items"
...
class Vegetable(Implicit):
...
def texture(self):
"Returns the texture of the vegetable."
class Fruit(Implicit):
...
def color(self):
"Returns the color of the fruit."
basket=Basket()
basket.apple=Fruit()
basket.carrot=Vegetable()
The URL /basket/apple/numberOfItems uses acquisition along
containment lines to publish the numberOfItems method
(assuming that apple doesn't have a numberOfItems
attribute). However, the URL /basket/carrot/apple/texture
uses acquisition to locate the texture method from the apple
object's context, rather than from its container. While this
distinction may be obscure, the guiding idea is to keep URLs as
simple as possible. By keeping acquisition simple and along
containment lines your application increases in clarity, and
decreases in fragility.
Anonymous User - Jan. 11, 2002 11:58 am - typo /your/you/. What then is the positive side of aquisition, if its freedom is dangerous and a more restrictive name resolution would suffice?
Anonymous User - Dec. 5, 2001 9:23 am - Thus, the first URL returns the number of apples in the basket (i.e. 1)? And the second URL returns the texture of the carrot?
rogererens - Dec. 7, 2001 6:14 am - Read chapter 5, Acquisition first. I think it's instructional to state that the first URL is equivalent to /basket/carrot/apple/numberOfItems. The number of contained items in the basket is 2 (a carrot and an apple). Furthermore, the second URL uses acquisition by context because the method texture cannot be acquired by containment (i.e. not in apple nor in its container, basket). Please correct me if I'm wrong.
Anonymous User - Aug. 16, 2003 12:56 pm: I don't begin to comprehend all this guff - and why's it here anyway? Doesn't seem to add anything to the matter of publishing - I suggest it's best left to the real chapter on Acquisition...
A second usage of acquisition in traversal concerns the
request. The publisher tries to make the request available to
the published object via acquisition. It does this by wrapping
the first object in an acquisition wrapper that allows it to
acquire the request with the name REQUEST. This means that you
can normally acquire the request in the published object like
so:
request=self.REQUEST # for implicit acquirers
request=self.aq_acquire('REQUEST') # for explicit acquirers
Of course, this will not work if your objects do not support
acquisition, or if any traversed objects have an attribute named
REQUEST.
Finally, acquisition has a totally different role in object publishing related to security which we'll examine next.
Traversal and Security
As the publisher moves from object to object during traversal it makes security checks. The current user must be authorized to access each object along the traversal path. The publisher controls access in a number of ways. For more information about Zope security, see Chapter 6, "Security".
Basic Publisher Security
The publisher imposes a few basic restrictions on traversable objects. These restrictions are the same of those for publishable objects. As previously stated, publishable objects must have doc strings and must not have names beginning with underscore.
The following details are not important if you are using the Zope framework. However, if your are publishing your own modules, the rest of this section will be helpful.
The publisher checks authorization by examining the
__roles__ attribute of each object as it performs
traversal. If present, the __roles__ attribute should be
None or a list of role names. If it is None, the object is
considered public. Otherwise the access to the object requires
validation.
Some objects such as functions and methods do not support
creating attributes (at least they didn't before Python
2). Consequently, if the object has no __roles__ attribute,
the publisher will look for an attribute on the object's
parent with the name of the object followed by
__roles__. For example, a function named getInfo would
store its roles in its parent's getInfo__roles__ attribute.
If an object has a __roles__ attribute that is not empty and
not None, the publisher tries to find a user database to
authenticate the user. It searches for user databases by
looking for an __allow_groups__ attribute, first in the
published object, then in the previously traversed object, and
so on until a user database is found.
When a user database is found, the publisher attempts to validate the user against the user database. If validation fails, then the publisher will continue searching for user databases until the user can be validated or until no more user databases can be found.
The user database may be an object that provides a validate method:
validate(request, http_authorization, roles)
where request is a mapping object that contains request
information, http_authorization is the value of the HTTP
Authorization header or None if no authorization header
was provided, and roles is a list of user role names.
The validate method returns a user object if succeeds, and
None if it cannot validate the user. See Chapter 6 for more
information on user objects. Normally, if the validate method
returns None, the publisher will try to use other user
databases, however, a user database can prevent this by
raising an exception.
Anonymous User - May 18, 2002 9:59 pm: dshafer - if *it* succeeds (word missing)
If validation fails, Zope will return an HTTP header that
causes your browser to display a user name and password
dialog. You can control the realm name used for basic
authentication by providing a module variable named
__bobo_realm__. Most web browsers display the realm name in
the user name and password dialog box.
If validation succeeds the publisher assigns the user object
to the request variable, AUTHENTICATED_USER. The publisher
places no restriction on user objects.
Anonymous User - Aug. 11, 2002 5:18 pm: Worth noting here that direct access to AUTHENTICATED_USER is deprecated for security reasons?
Zope Security
When using Zope rather than publishing your own modules, the
publisher uses acquisition to locate user folders and perform
security checks. The upshot of this is that your published
objects must inherit from Acquisition.Implicit or
Acquisition.Explicit. See Chapter 5, "Acquisition", for more
information about these classes. Also when traversing each
object must be returned in an acquisition context. This is
done automatically when traversing via getattr, but you must
wrap traversed objects manually when using __getitem__ and
__bobo_traverse__. For example:
class Example(Acquisition.Explicit):
...
def __bobo_traverse__(self, name, request):
...
next_object=self._get_next_object(name)
return next_object.__of__(self)
Anonymous User - Nov. 6, 2002 10:57 am: It may be worth making a reference to this from the reference to __bobo_traverse__ earlier in the chapter.
Anonymous User - Jan. 18, 2002 7:26 pm - There's a missing "for" here: "See Chapter 5, Acquisition more information...".
Additionally you will need to make security declarations on
your traversed object using ClassSecurityInfo as described
in Chapter 6, "Security".
Anonymous User - Jan. 11, 2002 12:10 pm - invalid href Acqisition
Finally, traversal security can be circumvented with the
__allow_access_to_unprotected_subobjects__ attribute as
described in Chapter 6, "Security".
Anonymous User - Sep. 27, 2002 6:06 am: It isn't described anywhere in chapter 6 (or anywhere else in this book for that matter).
Environment Variables
You can control some facets of the publisher's operation by setting environment variables.
-
Z_DEBUG_MODE - Sets debug mode. In debug mode tracebacks are
not hidden in error pages. Also debug mode causes
DTMLFileobjects, External Methods and help topics to reload their contents from disk when changed. You can also set debug mode with the-Dswitch when starting Zope. -
Z_REALM - Sets the basic authorization realm. This controls
the realm name as it appears in the web browser's username and
password dialog. You can also set the realm with the
__bobo_realm__module variable, as mentioned previously. -
PROFILE_PUBLISHER - Turns on profiling and sets the name of the profile file. See the Python documentation for more information about the Python profiler.
Anonymous User - Aug. 16, 2003 1:00 pm: Does this still stand true in the light of the changes with i.e. Zope 2.7 ?
Many more options can be set using switches on the startup script. See the Zope Administrator's Guide for more information.
Testing
ZPublisher comes with built-in support for testing and working with the Python debugger. This topic is covered in more detail in Chapter 7, "Testing and Debugging".
Publishable Module
If you are using the Zope framework, this section will be
irrelevant to you. However, if you are publishing your own
modules with ZPublisher read on.
The publisher begins the traversal process by locating an object in the module's global namespace that corresponds to the first element of the path. Alternately the first object can be located by one of two hooks.
Anonymous User - Feb. 28, 2002 3:31 pm - isn't the first name on the path the name of the module itself?
If the module defines a web_objects or bobo_application
object, the first object is searched for in those objects. The
search happens according to the normal rules of traversal, using
__bobo_traverse__, getattr, and __getitem__.
The module can receive callbacks before and after traversal. If
the module defines a __bobo_before__ object, it will be called
with no arguments before traversal. Its return value is
ignored. Likewise, if the module defines a __bobo_after__
object, it will be called after traversal with no
arguments. These callbacks can be used for things like acquiring
and releasing locks.
Calling the Published Object
Now that we've covered how the publisher located the published object and what it does with the results of calling it, let's take a closer look at how the published object is called.
Anonymous User - Nov. 26, 2001 2:02 pm - published object can be accessed by REQUEST['PUBLISHED'], this is especially useful if you are publishing a method inside of a container above the PUBLISHED object.
The publisher marshals arguments from the request and automatically makes them available to the published object. This allows you to accept parameters from web forms without having to parse the forms. Your objects usually don't have to do anything special to be called from the web. Consider this function:
def greet(name):
"greet someone"
return "Hello, %s" % name
You can provide the name argument to this function by calling it
with a URL like greet?name=World. You can also call it with a
HTTP POST request which includes name as a form variable.
In the next sections we'll take a closer look at how the publisher marshals arguments.
Marshalling Arguments from the Request
The publisher marshals form data from GET and POST
requests. Simple form fields are made available as Python
strings. Multiple fields such as form check boxes and multiple
selection lists become sequences of strings. File upload fields
are represented with FileUpload objects. File upload objects
behave like normal Python file objects and additionally have a
filename attribute which is the name of the file and a
headers attribute which is a dictionary of file upload
headers.
The publisher also marshals arguments from CGI environment
variables and cookies. When locating arguments, the publisher
first looks in CGI environment variables, then other request
variables, then form data, and finally cookies. Once a variable
is found, no further searching is done. So for example, if your
published object expects to be called with a form variable named
SERVER_URL, it will fail, since this argument will be
marshaled from the CGI environment first, before the form data.
Anonymous User - Nov. 15, 2002 1:35 pm: Could readers find the use of the term 'fail' somewhat confusing here? I'm guessing that the 'published onject' will still get called OK, but that the value of the 'SERVER_URL' argument would be other than that expected?
The publisher provides a number of additional special variables
such as URL0 which are derived from the request. These are
covered in the HTTPRequest API documentation.
Argument Conversion
The publisher supports argument conversion. For example consider this function:
def onethird(number):
"returns the number divided by three"
return number / 3.0
Anonymous User - Apr. 25, 2005 2:11 pm:
def onethird():
"returns the number divided by three"
return int(number) / 3.0
onethird?number=66
Is this legal?
This function cannot be called from the web because by default the publisher marshals arguments into strings, not numbers. This is why the publisher provides a number of converters. To signal an argument conversion you name your form variables with a colon followed by a type conversion code. For example, to call the above function with 66 as the argument you can use this URL
onethird?number:int=66 The publisher supports many converters:- boolean
- Converts a variable to true or false. Variables that are 0, None, an empty string, or an empty sequence are false, all others are true.
- int
- Converts a variable to a Python integer.
- long
- Converts a variable to a Python long integer.
- float
- Converts a variable to a Python floating point number.
- string
- Converts a variable to a Python string.
- required
- Raises an exception if the variable is not present or is an empty string.
- ignore_empty
- Excludes a variable from the request if the variable is an empty string.
- date
- Converts a string to a DateTime object. The formats
accepted are fairly flexible, for example
10/16/2000,12:01:13 pm. - list
- Converts a variable to a Python list of values, even if there is only one value.
- tuple
- Converts a variable to a Python tuple of values, even if there is only one value.
- lines
- Converts a string to a Python list of values by splitting the string on line breaks.
- tokens
- Converts a string to a Python list of values by splitting the string on spaces.
- text
- Converts a variable to a string with normalized line breaks. Different browsers on various platforms encode line endings differently, so this converter makes sure the line endings are consistent, regardless of how they were encoded by the browser.
Anonymous User - Nov. 15, 2002 1:37 pm: Asserting that 'This function cannot be called from the web' seems inaccurate or incomplete - especially considering the subsequent explanation.
Anonymous User - Nov. 20, 2003 1:17 am: This list is missing ustring.
If the publisher cannot coerce a request variable into the type required by the type converter it will raise an error. This is useful for simple applications, but restricts your ability to tailor error messages. If you wish to provide your own error messages, you should convert arguments manually in your published objects rather than relying on the publisher for coercion. Another possibility is to use JavaScript to validate input on the client-side before it is submitted to the server.
You can combine type converters to a limited extent. For example you could create a list of integers like so:
<input type="checkbox" name="numbers:list:int" value="1"> <input type="checkbox" name="numbers:list:int" value="2"> <input type="checkbox" name="numbers:list:int" value="3">
In addition to these type converters, the publisher also supports method and record arguments.
Anonymous User - July 17, 2002 5:56 pm: This is covered pretty thoroughly in the Zope Book's Chapter 10 -- perhaps a reference would be more appropriate than duplicating the content?
Anonymous User - Sep. 16, 2002 2:09 pm: I feel that the explaination here is better than the explanation in the Zope Book.
Anonymous User - Oct. 8, 2002 11:17 am: v2 of the Zope book in chapter 10 refers to actions rather than methods. Also, it should be described somewhere what should go in the <form> element's "action" attribute: is it just an empty string as per the Zope Book example?
Anonymous User - Aug. 9, 2004 6:03 pm: What an ugly hack. The type of coercion to apply should be specified in the method that is published, not in the parameter names inside the HTTP request, where it is controlled by the user making the request. Of course you don't have to use this scheme and can instead use explicit coercion code, but why allow coercion specs in parameter names at all then?
Method Arguments
Sometimes you may wish to control which object is published based on form data. For example, you might want to have a form with a select list that calls different methods depending on the item chosen. Similarly, you might want to have multiple submit buttons which invoke a different method for each button.
The publisher provides a way to select methods using form
variables through use of the method argument type. The
method type allows the request PATH_INFO to be augmented
using information from a form item name or value.
If the name of a form field is :method, then the value of
the field is added to PATH_INFO. For example, if the
original PATH_INFO is foo/bar and the value of a :method
field is x/y, then PATH_INFO is transformed to
foo/bar/x/y. This is useful when presenting a select
list. Method names can be placed in the select option values.
If the name of a form field ends in :method then the part of
the name before :method is added to PATH_INFO. For
example, if the original PATH_INFO is foo/bar and there is
a x/y:method field, then PATH_INFO is transformed to
foo/bar/x/y. In this case, the form value is ignored. This
is useful for mapping submit buttons to methods, since submit
button values are displayed and should, therefore, not contain
method names.
Only one method field should be provided. If more than one method field is included in the request, the behavior is undefined.
Record Arguments
Sometimes you may wish to consolidate form data into a structure rather than pass arguments individually. Record arguments allow you to do this.
The record type converter allows you to combine multiple
form variables into a single input variable. For example:
<input name="date.year:record:int"> <input name="date.month:record:int"> <input name="date.day:record:int">
This form will result in a single variable, date, with
attributes year, month, and day.
Anonymous User - Apr. 25, 2005 3:17 pm: how much white space can I add I rove white space It's white.
Anonymous User - Apr. 25, 2005 3:19 pm: not much, I'll say that.
You can skip empty record elements with the ignore_empty
converter. For example:
<input type="text" name="person.email:record:ignore_empty">
When the email form field is left blank the publisher skips
over the variable rather than returning a null string as its
value. When the record person is returned it will not have
an email attribute if the user did not enter one.
You can also provide default values for record elements with
the default converter. For example:
<input type="hidden"
name="pizza.toppings:record:list:default"
value="All">
<select multiple name="pizza.toppings:record:list:ignore_empty">
<option>Cheese</option>
<option>Onions</option>
<option>Anchovies</option>
<option>Olives</option>
<option>Garlic<option>
</select>
The default type allows a specified value to be inserted
when the form field is left blank. In the above example, if
the user does not select values from the list of toppings, the
default value will be used. The record pizza will have the
attribute toppings and its value will be the list containing
the word "All" (if the field is empty) or a list containing
the selected toppings.
You can even marshal large amounts of form data into multiple
records with the records type converter. Here's an example:
<h2>Member One</h2> Name: <input type="text" name="members.name:records"><BR> Email: <input type="text" name="members.email:records"><BR> Age: <input type="text" name="members.age:int:records"><BR> <H2>Member Two</H2> Name: <input type="text" name="members.name:records"><BR> Email: <input type="text" name="members.email:records"><BR> Age: <input type="text" name="members.age:int:records"><BR>
This form data will be marshaled into a list of records named
members. Each record will have a name, email, and age
attribute.
Record marshalling provides you with the ability to create complex forms. However, it is a good idea to keep your web interfaces as simple as possible.
Exceptions
Unhandled exceptions are caught by the object publisher and are translated automatically to nicely formatted HTTP output.
When an exception is raised, the exception type is mapped to an HTTP code by matching the value of the exception type with a list of standard HTTP status names. Any exception types that do not match standard HTTP status names are mapped to "Internal Error" (500). The standard HTTP status names are: "OK", "Created", "Accepted", "No Content", "Multiple Choices", "Redirect", "Moved Permanently", "Moved Temporarily", "Not Modified", "Bad Request", "Unauthorized", "Forbidden", "Not Found", "Internal Error", "Not Implemented", "Bad Gateway", and "Service Unavailable". Variations on these names with different cases and without spaces are also valid.
Anonymous User - Dec. 5, 2001 11:16 am - Typo: Bad Gateway needs to be quoted
Anonymous User - Feb. 15, 2002 2:17 pm - Actually, if you view the structured text source, this isn't a typo. It *is* quoted, with a comma, and the word and between Gateway and Service. I think this is likely a structured text problem, not the author's fault.
An attempt is made to use the exception value as the body of the
returned response. The object publisher will examine the exception
value. If the value is a string that contains some white space,
then it will be used as the body of the return error message. If
it appears to be HTML, the error content type will be set to
text/html, otherwise, it will be set to text/plain. If the
exception value is not a string containing white space, then the
object publisher will generate its own error message.
There are two exceptions to the above rule:
- If the exception type is: "Redirect", "Multiple Choices"
"Moved Permanently", "Moved Temporarily", or "Not
Modified", and the exception value is an absolute URI, then
no body will be provided and a
Locationheader will be included in the output with the given URI. - If the exception type is "No Content", then no body will be returned.
Anonymous User - Dec. 5, 2001 11:18 am - Typos: No Content and Move Temporarily need quotes
Anonymous User - May 18, 2002 10:07 pm: dshafer - Comma needed between "Mutiple Choices" and "Moved Permanently".
When a body is returned, traceback information will be included in
a comment in the output. As mentioned earlier, the environment
variable Z_DEBUG_MODE can be used to control how tracebacks are
included. If this variable is set then tracebacks are included in
PRE tags, rather than in comments. This is very handy during
debugging.
Exceptions and Transactions
When Zope receives a request it begins a transaction. Then it begins the process of traversal. Zope automatically commits the transaction after the published object is found and called. So normally each web request constitutes one transaction which Zope takes care of for you. See Chapter 4. for more information on transactions.
If an unhandled exception is raised during the publishing
process, Zope aborts the transaction. As detailed in Chapter
4. Zope handles ConflictErrors by re-trying the request up to
three times. This is done with the zpublisher_exception_hook.
In addition, the error hook is used to return an error message
to the user. In Zope the error hook creates error messages by
calling the raise_standardErrorMessage method. This method is
implemented by SimpleItem.Item. It acquires the
standard_error_message DTML object, and calls it with
information about the exception.
You will almost never need to override the
raise_standardErrorMessage method in your own classes, since
it is only needed to handle errors that are raised by other
components. For most errors, you can simply catch the exceptions
normally in your code and log error messages as needed. If you
need to, you should be able to customize application error
reporting by overriding the standard_error_message DTML object
in your application.
Manual Access to Request and Response
You do not need to access the request and response directly most of the time. In fact, it is a major design goal of the publisher that most of the time your objects need not even be aware that they are being published on the web. However, you have the ability to exert more precise control over reading the request and returning the response.
Normally published objects access the request and response by listing them in the signature of the published method. If this is not possible you can usually use acquisition to get a reference to the request. Once you have the request, you can always get the response from the request like so:
response=REQUEST.RESPONSE
Anonymous User - Aug. 16, 2003 1:12 pm: an example of 'use acquisition to get the request' would be very useful here for us novices.
The APIs of the request and response are covered in the API documentation. Here we'll look at a few common uses of the request and response.
One reason to access the request is to get more precise information about form data. As we mentioned earlier, argument marshalling comes from a number of places including cookies, form data, and the CGI environment. For example, you can use the request to differentiate between form and cookie data:
cookies=REQUEST.cookies # a dictionary of cookie data form=REQUEST.form # a dictionary of form data
One common use of the response object is to set response headers. Normally the publisher in concert with the web server will take care of response headers for you. However, sometimes you may wish manually control headers:
RESPONSE.setHeader('Pragma', 'No-Cache')
Another reason to access the response is to stream response
data. You can do this with the write method:
while 1:
data=getMoreData() #this call may block for a while
if not data:
break
RESPONSE.write(data)
Here's a final example that shows how to detect if your method is being called from the web. Consider this function:
def feedParrot(parrot_id, REQUEST=None):
...
if REQUEST is not None:
return "<html><p>Parrot %s fed</p></html>" % parrot_id
The feedParrot function can be called from Python, and also from
the web. By including REQUEST=None in the signature you can
differentiate between being called from Python and being called
form the web. When the function is called from Python nothing is
returned, but when it is called from the web the function returns
an HTML confirmation message.
Anonymous User - Nov. 15, 2002 1:47 pm: typo: 'called form the web' should read 'called from the web'
Other Network Protocols
FTP
Zope comes with an FTP server which allows users to treat the
Zope object hierarchy like a file server. As covered in Chapter
3, Zope comes with base classes (SimpleItem and
ObjectManager) which provide simple FTP support for all Zope
objects. The FTP API is covered in the API reference.
To support FTP in your objects you'll need to find a way to represent your object's state as a file. This is not possible or reasonable for all types of objects. You should also consider what users will do with your objects once they access them via FTP. You should find out which tools users are likely to edit your object files. For example, XML may provide a good way to represent your object's state, but it may not be easily editable by your users. Here's an example class that represents itself as a file using RFC 822 format:
from rfc822 import Message
from cStringIO import StringIO
class Person(...):
def __init__(self, name, email, age):
self.name=name
self.email=email
self.age=age
def writeState(self):
"Returns object state as a string"
return "Name: %s\nEmail: %s\nAge: %s" % (self.name,
self.email,
self.age)
def readState(self, data):
"Sets object state given a string"
m=Message(StringIO(data))
self.name=m['name']
self.email=m['email']
self.age=int(m['age'])
The writeState and readState methods serialize and
unserialize the name, age, and email attributes to and
from a string. There are more efficient ways besides RFC 822 to
store instance attributes in a file, however RFC 822 is a simple
format for users to edit with text editors.
To support FTP all you need to do at this point is implement the
manage_FTPget and PUT methods. For example:
def manage_FTPget(self):
"Returns state for FTP"
return self.writeState()
def PUT(self, REQUEST):
"Sets state from FTP"
self.readState(REQUEST['BODY'])
You may also choose to implement a get_size method which
returns the size of the string returned by manage_FTPget. This
is only necessary if calling manage_FTPget is expensive, and
there is a more efficient way to get the size of the file. In
the case of this example, there is no reason to implement a
get_size method.
One side effect of implementing PUT is that your object now
supports HTTP PUT publishing. See the next section on WebDAV for
more information on HTTP PUT.
That's all there is to making your object work with FTP. As you'll see next WebDAV support is similar.
WebDAV
WebDAV is a protocol for collaboratively edit and manage files on remote servers. It provides much the same functionality as FTP, but it works over HTTP.
Anonymous User - Mar. 5, 2004 6:27 pm: change "for collaboratively edit and manage files" to read "to collaboratively edit and manage files (roy)"
It is not difficult to implement WebDAV support for your objects. Like FTP, the most difficult part is to figure out how to represent your objects as files.
Your class must inherit from webdav.Resource to get basic DAV
support. However, since SimpleItem inherits from Resource,
your class probably already inherits from Resource. For
container classes you must inherit from
webdav.Collection. However, since ObjectManager inherits
from Collection you are already set so long as you inherit
from ObjectManager.
In addition to inheriting from basic DAV classes, your classes
must implement PUT and manage_FTPget. These two methods are
also required for FTP support. So by implementing WebDAV
support, you also implement FTP support.
The permissions that you assign to these two methods will control the ability to read and write to your class through WebDAV, but the ability to see your objects is controlled through the "WebDAV access" permission.
Supporting Write Locking
Write locking is a feature of WebDAV that allows users to put
a lock on objects they are working on. Support write locking
is easy. To implement write locking you must assert that your
class implements the WriteLockInterface. For example:
from webdav.WriteLockInterface import WriteLockInterface
class MyContentClass(OFS.SimpleItem.Item, Persistent):
__implements__ = (WriteLockInterface,)
Anonymous User - Nov. 15, 2002 2:21 pm: typo: 'Support write locking' should read e.g. 'Supporting write locking'
It's sufficient to inherit from SimpleItem.Item, since it
inherits from webdav.Resource, which provides write locking
along with other DAV support.
In addition, your PUT method should begin with calls to
dav__init and dav_simpleifhandler. For example:
def PUT(self, REQUEST, RESPONSE):
"""
Implement WebDAV/HTTP PUT/FTP put method for this object.
"""
self.dav__init(REQUEST, RESPONSE)
self.dav__simpleifhandler(REQUEST, RESPONSE)
...
Finally your class's edit methods should check to determine
whether your object is locked using the ws_isLocked
method. If someone attempts to change your object when it is
locked you should raise the ResourceLockedError. For
example:
from webdav import ResourceLockedError
class MyContentClass(...):
...
def edit(self, ...):
if self.ws_isLocked():
raise ResourceLockedError
...
WebDAV support is not difficult to implement, and as more WebDAV editors become available, it will become more valuable. If you choose to add FTP support to your class you should probably go ahead and support WebDAV too since it is so easy once you've added FTP support.
XML-RPC
XML-RPC is a light-weight Remote Procedure Call protocol that uses XML for encoding and HTTP for transport. Fredrick Lund maintains a Python XML-RPC module.
All objects in Zope support XML-RPC publishing. Generally you
will select a published object as the end-point and select one
of its methods as the method. For example you can call the
getId method on a Zope folder at http://example.com/myfolder
like so:
import xmlrpclib
folder=xmlrpclib.Server('http://example.com/myfolder')
ids=folder.getId()
You can also do traversal via a dotted method name. For example:
import xmlrpclib
# traversal via dotted method name
app=xmlrpclib.Server('http://example.com/app')
id1=app.folderA.folderB.getId()
# walking directly up to the published object
folderB=xmlrpclib.Server('http://example.com/app/folderA/folderB')
id2=folderB.getId()
print id1==id2
This example shows different routes to the same object publishing call.
XML-RPC supports marshalling of basic Python types for both publishing requests and responses. The upshot of this arrangement is that when you are designing methods for use via XML-RPC you should limit your arguments and return values to simple values such as Python strings, lists, numbers and dictionaries. You should not accept or return Zope objects from methods that will be called via XML-RPC.
Anonymous User - Aug. 18, 2002 9:08 pm: Hm, I keep getting the same kind of error when trying these example calls to 'getId()' etc.: <Fault -1: 'Unexpected Zope exception: cannot marshal <extension class Acquisition.ImplicitAcquirerWrapper at 401a8840> objects'> So this is the kind of Zope object that won't be returned? I'd love to see some *working* examples of XML-RPC in Zope (please).
godefroy - May 27, 2004 6:29 pm:
The simpliest possible usage of XMLRPC in Zope:
As you probably know, "files" are folders' methods in Zope. So, you can put a Page Template in root
directory, and name it abc. Now abs is a method of / folder. Later you can put something more dynamic instead
of Page Template. For now, just delete contents of abc Page Template and replace them with single line of
text: "hello world".
This is a working example of XMLRPC Server for Zope. Cool, isn't it?
To test it:
1) run python
2) issue commands:
>>> import xmlrpclib
>>> s = xmlrpclib.Server('http://localhost:8080/')
>>> s.abc()
3) you should get methods result:
'hello, world\n'
(Assumed that Zope is on localhost:8080, and you have abc method (file, page template, whatever) in root
directory.)
XML-RPC does not support keyword arguments. This is a problem if
your method expect keyword arguments. This problem is
noticeable when calling DTMLMethods and DTMLDocuments with XML-RPC.
Normally a DTML object should be called with the request as the
first argument, and additional variables as keyword arguments.
You can get around this problem by passing a dictionary as the
first argument. This will allow your DTML methods and documents
to reference your variables with the var tag.
However, you cannot do the following:
<dtml-var expr="REQUEST['argument']">
Although the following will work:
<dtml-var expr="_['argument']">
This is because in this case arguments are in the DTML namespace, but they are not coming from the web request.
In general it is not a good idea to call DTML from XML-RPC since DTML usually expects to be called from normal HTTP requests.
One thing to be aware of is that Zope returns false for
published objects which return None since XML-RPC has no concept
of null.
Another issue you may run into is that xmlrpclib does not yet
support HTTP basic authentication. This makes it difficult to
call protected web resources. One solution is to patch
xmlrpclib. Another solution is to accept authentication
credentials in the signature of your published method.
Anonymous User - Dec. 5, 2003 6:12 pm: This is false. At least with the most recent version of Zope/CMF/Plone (Plone 1.5), basic authentication is supported and working. (I just tested it.)
panxing_personal - Feb. 15, 2005 1:44 am: could zope use corba to communate with other services? Thanks a lot!
Summary
Object publishing is a simple and powerful way to bring objects to the web. Two of Zope's most appealing qualities is how it maps objects to URLs, and you don't need to concern yourself with web plumbing. If you wish, there are quite a few details that you can use to customize how your objects are located and published.
Anonymous User - Nov. 4, 2002 1:11 pm: Note additional documentation for Zope 2.6+ wrt Unicode and object publishing is at http://www.zope.org/Members/htrd/howto/unicode-zdg-changes and http://www.zope.org/Members/htrd/howto/unicode.